
먼저 JPA란 Java Persistence API의 약자로 자바 ORM 기술에 대한 API 표준 명세이며 대표적인 구현체로는 Hibernate가 있습니다.
JPA에서 가장 중요한 개념 중 하나인 영속성 컨텍스트(Persistence Context)의 특징에 대해 함께 알아보겠습니다.
특징에는 크게 다섯 가지가 있습니다.
- 1차 캐시 (
First Level Cache) - 동일성 보장 (
Identify) - 쓰기 지연 (
Write-behind) - 변경 감지 (
Dirty Checking) - 지연 로딩 (
Lazy Loading)
본격적으로 들어가기 전에 혹시 아래와 비슷한 코드를 보시거나 작성해보신 적이 있으신가요?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// 이런 코드를 보신적이 있나요?
fun main(args: Array) {
val emf = Persistence.createEntityManagerFactory("default")
val em = emf.createEntityManager()
val tx = em.transaction
tx.begin()
try {
val member = Member().apply {
name = "배모군"
address = "서울"
}
em.persist(member)
} catch (e: Exception) {
e.printStackTrace()
tx.rollback()
} finally {
em.close()
}
emf.close()
}
만약 위와 같은 코드를 처음 보신다면 JPA에 대해 더 학습이 필요할 수 있습니다.
요즘은 스프링 부트와 Spring Data JPA에서 제공하는 추상화한 Repository를 사용하여 개발을 하는 경우가 많지만
실제 구현체는 위와 같은 코드와 비슷하게 작성되어 있습니다.
그래서 샘플 코드는 직접 EntityManager를 사용하여 작성하였습니다.
프로젝트 구성
말씀드린대로 EntityManager를 직접 사용하여 샘플 코드를 작성하였지만 설정의 편의를 위하여
Spring Data JPA Starter를 의존성으로 넣고 스프링 부트에서 사용하는 application.yml로 설정 하였습니다.
또한 자바가 아닌 코틀린으로 작성하니 참고 바랍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
// build.gradle.kts
plugins {
kotlin("jvm") version "1.3.61"
kotlin("plugin.spring") version "1.3.61"
kotlin("plugin.jpa") version "1.3.61"
id("org.springframework.boot") version "2.2.2.RELEASE"
idea
}
apply {
plugin("io.spring.dependency-management")
}
allOpen {
annotation("javax.persistence.Entity")
annotation("javax.persistence.MappedSuperclass")
annotation("javax.persistence.Embeddable")
}
group = "dev.baesangwoo"
version = "1.0-SNAPSHOT"
repositories {
mavenCentral()
}
dependencies {
implementation(kotlin("stdlib-jdk8"))
implementation(kotlin("reflect"))
implementation("org.springframework.boot:spring-boot-starter-data-jpa")
runtimeOnly("mysql:mysql-connector-java")
testImplementation("org.springframework.boot:spring-boot-starter-test") {
exclude(group = "org.junit.vintage", module = "junit-vintage-engine")
}
}
tasks {
compileKotlin {
kotlinOptions {
freeCompilerArgs = listOf("-Xjsr305=strict")
jvmTarget = "1.8"
}
}
compileTestKotlin {
kotlinOptions {
freeCompilerArgs = listOf("-Xjsr305=strict")
jvmTarget = "1.8"
}
}
test {
useJUnitPlatform()
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# resources/application.yml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: password
jpa:
properties:
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
hibernate:
format_sql: true
use_sql_comments: true
hibernate:
ddl-auto: create
show-sql: true
logging.level.org.hibernate.type.descriptor.sql.BasicBinder: trace
Entity 작성
1:n 구조를 갖는 Entity 두 가지를 간단히 작성하였습니다.
또한 쓰기 지연의 재현을 눈으로 보기 쉽게 @Id 필드에 @GeneratedValue를 선언하지 않았습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Entity
class Team(
@Id
var id: Long,
var name: String
)
@Entity
@Table(name = "MEMBER")
class Member(
@Id
var id: Long,
@ManyToOne(fetch = FetchType.LAZY)
var team: Team,
var name: String,
var address: String
)
테스트 코드 작성
테스트를 위해 JUnit5를 사용하였고 JPA만 테스트하기 위해 @DataJpaTest를 사용 하였습니다.
대략적인 구성은 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
@ExtendWith(SpringExtension::class) // junit5
@DataJpaTest
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE) // 테스트 데이터베이스를 h2로 변경하지 않음
@Rollback(false) // 테스트 후 롤백하지 않음
@DisplayName("영속성 컨텍스트 테스트")
internal class PersistenceContextTest {
@PersistenceContext // 기본 엔티티매니저
private lateinit var em: EntityManager
@Test
@DisplayName("1차 캐시 테스트")
fun testFirstLevelCache() {
// code ..
}
@Test
@DisplayName("동일성 테스트")
fun testIdentity() {
// code ..
}
@Test
@DisplayName("쓰기 지연 테스트")
fun testWriteBehind() {
// code ..
}
@Test
@DisplayName("변경 감지 테스트")
fun testDirtyChecking() {
// code ..
}
@Test
@DisplayName("지연 로딩 테스트")
fun testLazyLoading() {
// code ..
}
}
이제부터 영속성 컨텍스트의 각 특징을 재현과 함께 설명 해보겠습니다. :)
1차 캐시 (First Level Cache)
영속화된 엔티티를 저장하여 @id값이 같은 엔티티를 찾을 때 직접 DB에 쿼리 실행을 요청하지 않고 엔티티가 저장된 공간에서 가져오게 되는데 이 공간을 1차 캐시라 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Test
@DisplayName("1차 캐시 테스트")
fun testFirstLevelCache() {
val randomNum = (100..200L).random()
team = Team(
id = randomNum,
name = "팀_$randomNum"
)
em.persist(team)
// select 쿼리가 실행되지 않고 1차 캐시에서 가져옴.
em.find(Team::class.java, team.id)
}
 1차 캐시 테스트 결과
1차 캐시 테스트 결과
위 코드를 실행하면 find 구문이 있지만 select 쿼리가 실행되지 않는 것을 확인할 수 있습니다.
이미 1차 캐시에 동일한 아이디를 가지고 있는 엔티티가 존재하기때문에 데이터베이스로 쿼리를 요청하지 않고 캐시를 가져옵니다.
동일성 보장 (Identity)
동일한 @id값으로 검색한 엔티티는 동일성이 보장됩니다.
마치 리스트에서 데이터를 가져오듯 @id값이 동일하다면 해당 엔티티의 동일성을 보장해줍니다.
즉, 동일한 레퍼런스라는 뜻입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@Test
@DisplayName("동일성 테스트")
fun testIdentity() {
val randomNum = (100..200L).random()
val team = Team(
id = randomNum,
name = "팀_$randomNum"
)
em.persist(team)
// select 쿼리가 실행되지 않고 1차 캐시에서 가져옴.
val findTeam = em.find(Team::class.java, team.id)
// 동등성 (equality)
assertEquals(findTeam, team)
// 동일성 (identity)
assertSame(findTeam, team)
}
 동일성 테스트 결과
동일성 테스트 결과
영속화된 객체를 1차캐시에서 가져와 비교를하면 동등성은 물론이고 동일성까지 보장되어 테스트가 성공하는 것을 볼 수 있습니다.
쓰기 지연 (Write-behind)
한 트랜잭션안에서 여러번 persist 메소드를 호출하여 DB에 저장을 시도할 때 persist 함수가 호출된 시점이 아닌
트렌잭션이 커밋되는 시점에 한 번에 insert 쿼리가 실행되어 네트워크 비용을 줄일 수 있고
트랜잭션이 커밋되지 않거나 중간에 의도치 않은 익셉션이 발생하면 트렌잭션이 롤백이되어 DB에 데이터가 반영되지 않습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Test
@DisplayName("쓰기 지연 테스트")
fun testWriteBehind() {
println("========================")
val myTeam = Team(
id = 2929494L,
name = "쓰기지연팀"
)
// 쿼리가 출력문 사이에 찍히지 않고 트랜잭션이 커밋될 때 (메소드 끝) 찍힘
em.persist(myTeam)
println("========================")
}
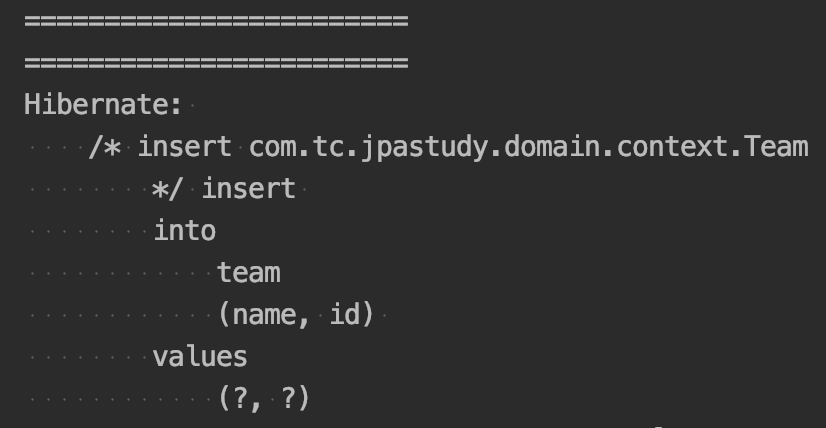 쓰기 지연 테스트 결과
쓰기 지연 테스트 결과
코드에서는 출력문 사이에 persist 메소드가 작성되어 있지만 실제 쿼리는 그 뒤에 찍히는 것이 보입니다.
정확히는 커밋 시점에 찍히는데 이 테스트에서는 메소드 종료 시점이 커밋 시점입니다.
변경 감지 (Dirty Checking)
영속화된 엔티티의 값을 변경한다면 다시 persist 메소드를 호출하여 DB에 명령을 보내는 것이 아니라
트렌잭션이 커밋되는 시점에 엔티티의 데이터가 변경이 되었다면 update 쿼리 실행을 요청합니다.
이는 1차 캐시에 영속화 시점의 스냅샷이 존재하기 때문입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@Test
@DisplayName("변경 감지 테스트")
fun testDirtyChecking() {
val randomNum = (100..200L).random()
val team = Team(
id = randomNum,
name = "팀_$randomNum"
)
em.persist(team)
// 프로퍼티의 값을 변경만 하면 종료 전 변경된 사항을 커밋할떄 판단하여 update 쿼리 실행
team.name = "TD"
}
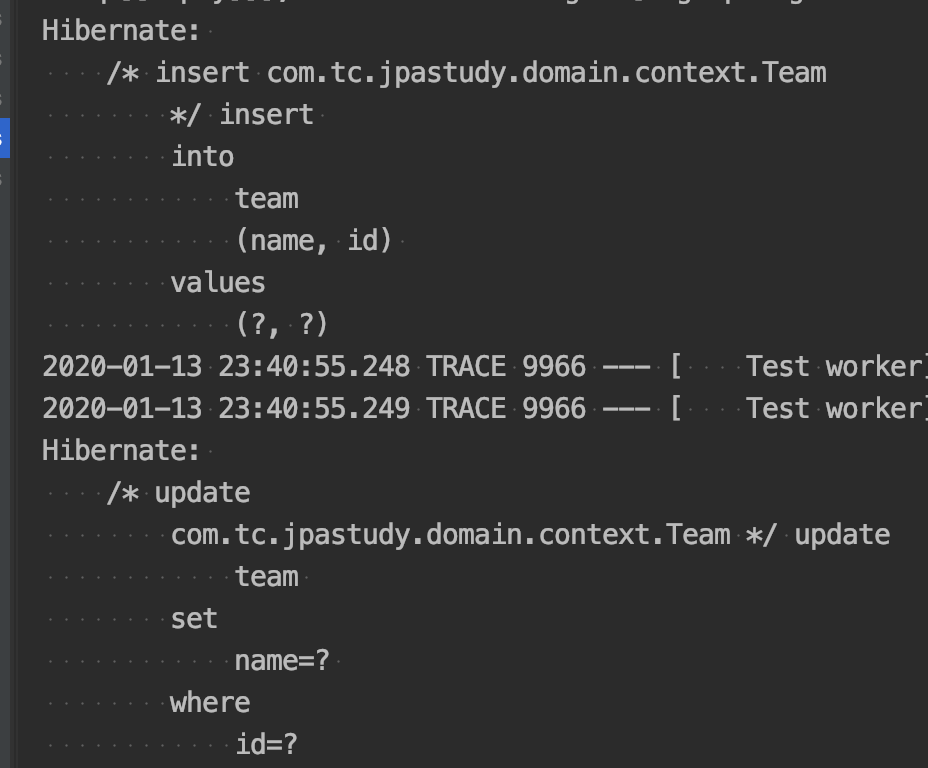 변경 감지 테스트 결과
변경 감지 테스트 결과
로그에 보이듯 값을 변경 후 다시 persist 메소드를 호출하지 않아도 업데이트 쿼리가 실행되는 것을 볼 수 있습니다. 영속성 컨텍스트에서 커밋 시점에 스냅샷과 비교하여 변경 사항이 있을 경우에만 업데이트 쿼리를 요청합니다.
지연 로딩 (Lazy Loading)
@ManyToOne 등 의 엔티티간 연관 관계가 맺어져 있는 엔티티를 검색할 때 연관 관계가 있는 엔티티는
프록시 데이터로 채우고 실제로 사용할 때 검색하게 하는 지연 로딩이 되어 불필요한 쿼리를 실행하지 않게 도와 줍니다.
필요에 따라서는 연관 관계가 있는 엔티티와 Join 하는 쿼리로 실행시킬 수도 있으나
기본적으로는 지연 로딩을 사용하는게 애플리케이션 성능 향상에 도움이 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
@Test
@DisplayName("지연 로딩 테스트")
fun testLazyLoading() {
val randomNum = (100..200L).random()
val team = Team(
id = randomNum,
name = "팀_$randomNum"
)
val member = Member(
id = randomNum,
team = team, // n:1 엔티티 주입
name = "배모군_$randomNum",
address = "서울_$randomNum"
)
em.persist(team)
em.persist(member)
// flush를 실행하면 쌓인 쿼리를 실행합니다.
em.flush()
// clear를 실행하면 영속성 컨텍스트가 가지고 있는 엔티티를 모두 제거합니다. (1차 캐시 정리)
em.clear()
val findMember = em.find(Member::class.java, member.id)
println("Member에서 Team을 참조하기 전 : ${findMember.address}")
// team을 참조할 때 team select 쿼리가 실행됨
println("Member에서 Team 참조 : ${findMember.team.name}")
}
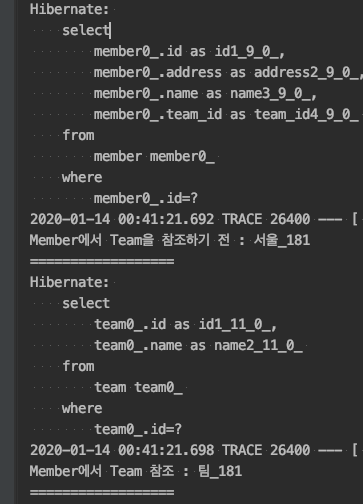 지연 로딩 테스트 결과
지연 로딩 테스트 결과
Member 엔티티를 조회 후 실제로 Team 엔티티의 값을 사용할 때 Team을 조회하는 쿼리가 실행되는 것을 볼 수 있습니다.
단, @ManyToOne 애노테이션에 fetch 조건을 Lazy로 선언해 주셔야 가능합니다.
이렇게 간단하게 영속성 컨텍스트의 다섯가지 특징을 간단히 알아봤습니다.
애플리케이션의 성능 향상의 방법은 다양하게 존재하지만 JPA를 사용한다면
이 다섯 가지 특징을 잘 이해하고 사용하면 좋은 알고리즘 만큼 큰 성능 향상을 느낄 수 있을 것이라고 생각합니다.
더불어 JPA를 공부하고 싶은 분들께 누구나 추천하는 이 책을 추천 드리며 이만 마치겠습니다.
감사합니다.